반복문의 종류
테라폼에서 제공하는 반복문의 종류는 아래와 같습니다.
- count parameter
- for_each expressions
- for expressions
- for string directive(문자열 지시어)
count
count 만큼 리소스와 모듈 실행을 반복합니다.
실습 1 - IAM 유저 생성하기
아래 코드는 neo라는 유저를 3번 생성하게 되는데, 이름이 중복되므로 오류가 발생합니다.
1
2
3
4
resource "aws_iam_user" "count_user" {
count = 3
name = "jjikin"
}
중복 오류를 해결하기 위해서는 반복문 내 각각의 반복을 가리키는 인덱스를 사용해야합니다.
1
2
3
4
resource "aws_iam_user" "count_user" {
count = 3
name = "jjikin-${count.index}"
}

따라서 count를 사용할 때는 사용하려는 블록(리소스 등)에 대한 이해가 반드시 필요합니다.
실습 2 - 입력 변수를 사용하여 IAM 유저 생성하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# ..week5/variables.tf
variable "user_names" {
description = "Create IAM users with these names"
type = list(string)
default = ["jjikin", "radish", "beer"]
}
# main.tf
provider "aws" {
region = "ap-northeast-2"
profile = "ljyoon"
}
resource "aws_iam_user" "iam_user" {
count = length(var.user_names)
name = var.user_names[count.index]
}
# outputs.tf
output "second_arn" {
value = aws_iam_user.iam_user[1].arn
description = "The ARN for the second user"
}
output "all_arns" {
value = aws_iam_user.iam_user[*].arn
description = "The ARNs for all users"
}
- **var.
[ ]** - 테라폼에서도 여러 프로그래밍 언어에서 사용하는 배열 개념을 지원합니다. - length 함수(내장) - 주어진 값의 항목 수를 반환하는 함수. 배열, 문자열 및 맵을 대상으로 사용 가능합니다.
- IAM 사용자 전체의 ARN 출력을 위해서는 인덱스 대신 스플랫 splat 연산자인 * 를 사용합니다.

count 제약 사항
리소스나 모듈 전체에 대한 반복은 가능하지만 내부 인라인 블록을 반복할 수 없습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
resource "aws_autoscaling_group" "example" { launch_configuration = aws_launch_configuration.example.name vpc_zone_identifier = data.aws_subnets.default.ids target_group_arns = [aws_lb_target_group.asg.arn] health_check_type = "ELB" min_size = var.min_size max_size = var.max_size tag { ~~count = 2 (x)~~ key = "Name" value = var.env propagate_at_launch = true } }
count와 배열을 같이 사용할 때, 배열 내 순서 변경 시 의도한 결과가 반영되지 않을 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# CASE 1 variable "user_names" { description = "Create IAM users with these names" type = list(string) default = ["jjikin", "radish", "beer"] } # CASE 2 variable "user_names" { description = "Create IAM users with these names" type = list(string) default = ["radish", "jjikin", "beer"] } resource "aws_iam_user" "iam_user" { count = length(var.user_names) name = var.user_names[count.index] }
CASE 1을 통해 IAM 유저를 생성하고 CASE 2와 같이 리스트 내 순서를 변경했다면 사용자 입장에서는 변경된 사항이 없다고 생각할 수 있습니다.
하지만 테라폼은 jjikin 유저를 삭제하고 radish 유저를 다시 생성하려고 시도하며, radish 유저는 이미 존재하므로 에러가 발생합니다. 인덱스는 단순히 값이 있는 순서만 나타낼 뿐이며, 값에 대한 유효성 체크를 하지 않기 때문에 인덱스를 이용하여 접근 시 주의해야합니다.
![Untitled]()
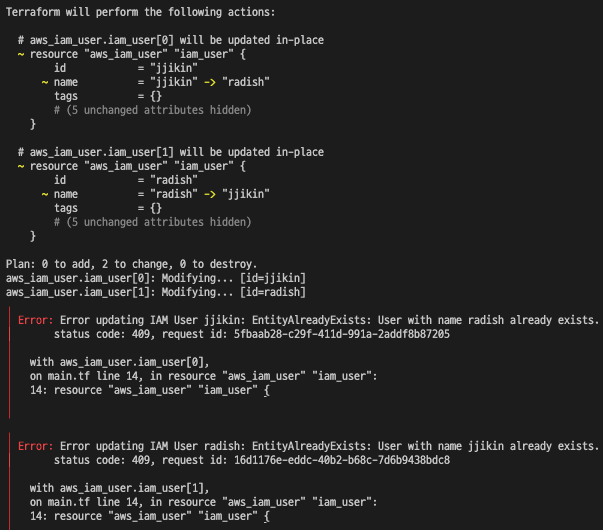
이를 해결하기 위해서는 for_each과 같이 인덱스를 사용하여 접근하지 않는 방법을 사용해야 합니다.
for_each
index가 아닌 each object로 접근하며 set, map 타입만 사용하여 전체 리소스의 여러 복사본 또는 리소스 내 인라인 블록의 여러 복사본을 생성 할 수 있습니다.
map, set 타입은 json 형식에서도 사용되는 key, value를 사용하는 타입으로 인덱스가 아닌 키로 접근합니다.
map 타입 사용 예시
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 입력 변수에 map타입 사용 variable "user_names" { description = "Create IAM users with these names" type = map(string) default = [ "chicken" : "jjikin", "side" : "radish", "drink" : "beer" } # 입력 변수 타입이 map이 아닌 경우 타입 변환 variable "user_names" { description = "Create IAM users with these names" type = list(string) default = ["jjikin", "radish", "beer"] } resource "aws_iam_user" "iam_user" { for_each = tomap(var.user_names) name = each.key }
for_each 구문
1 2 3 4 5
resource "<PROVIDER>_<TYPE>" "<NAME>" { for_each = <COLLECTION> [CONFIG ...] }
- COLLECTION : 루프를 처리할 set, map 또는 set, map 타입으로 변환된 타입
- CONFIG : each.key 또는 each.value를 사용하여 COLLECTION 내 Key와 Value에 접근할 수 있습니다.
실습 1 - IAM 유저 생성하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
provider "aws" {
region = "ap-northeast-2"
profile = "ljyoon"
}
variable "user_names" {
description = "Create IAM users with these names"
type = map(string)
default = { "chicken": "jjikin", "side" : "radish", "drink" : "beer" }
}
resource "aws_iam_user" "myiam" {
for_each = var.user_names
name = each.value
}
output "all_users" {
value = aws_iam_user.myiam
}
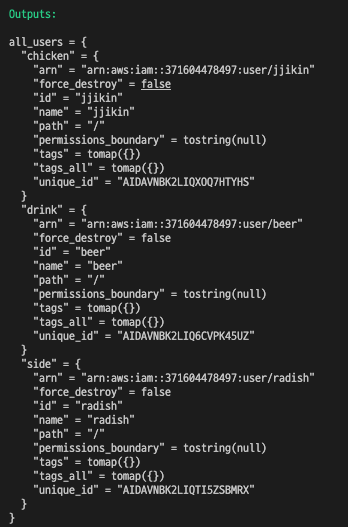
위의 전체 Output에서 필요한 값만 반환시키고 싶다면 내장 함수 values와 splat 표현식을 사용합니다.
1
2
3
4
# arn 값만 모두 출력
output "all_users" {
value = values(aws_iam_user.myiam)[*].arn
}
실습 2 - AutoScalingGroup 내 tag 인라인 블록 동적 생성하기
for_each 표현식을 통해 count 반복문 제약 사항이었던 내부 인라인 블록을 반복할 수 있습니다.
4주차에서 사용했던 코드를 재활용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# modules/services/webserver-cluster/variables.tf
variable "custom_tags" {
description = "Custom tags to set on the Instances in the ASG"
type = map(string)
default = {}
}
# stage/services/webserver-cluster/main.tf
module "webserver_cluster" {
source = "../../../../modules/services/webserver-cluster"
env = "stage"
instance_type = "t2.micro"
min_size = 1
max_size = 1
custom_tags = {
Owner = "team-jjikin"
ManagedBy = "terraform"
}
}
# modules/services/webserver-cluster/main.tf
...
resource "aws_autoscaling_group" "web-asg" {
name = "${var.env}-web-asg"
vpc_zone_identifier = [data.terraform_remote_state.vpc.outputs.pub-a-sn, data.terraform_remote_state.vpc.outputs.pub-c-sn]
...
tag {
key = "Name"
value = "${var.env}-web-asg"
propagate_at_launch = true
}
dynamic "tag" {
for_each = var.custom_tags
content {
key = tag.key
value = tag.value
propagate_at_launch = true
}
}
}
for expression
반복을 이용한 일괄 변환 작업이 필요한 경우 사용합니다.
for 구문
1 2 3 4 5
[ for <ITEM> in <COLLECTION; LIST or MAP or SET> : <OUTPUT(변환작업)> ] : [] 시 tuple 타입으로 반환 { for <ITEM> in <COLLECTION; LIST or MAP or SET> : <OUTPUT(변환작업)> } : {} 시 object 타입으로 반환
- ITEM : 리스트, 맵, 집합의 각 항목에 할당할 변수의 이름
사용 방법
terraform console 명령어를 통해 variable만 선언 후 output을 테스트 해볼 수 있습니다.
1 2 3 4 5
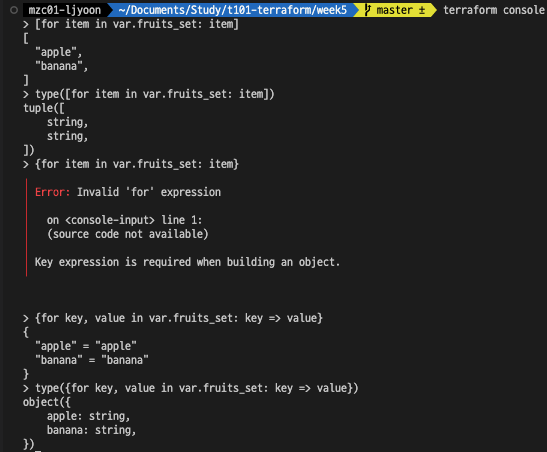
variable "fruits_set" { type = set(string) default = ["apple", "banana"] description = "fruit example" }
![- object 타입으로 반환하려면 key, value 형태를 사용해야한다.]() object 타입으로 반환하려면 key, value 형태를 사용해야한다.
object 타입으로 반환하려면 key, value 형태를 사용해야한다.1 2 3 4 5
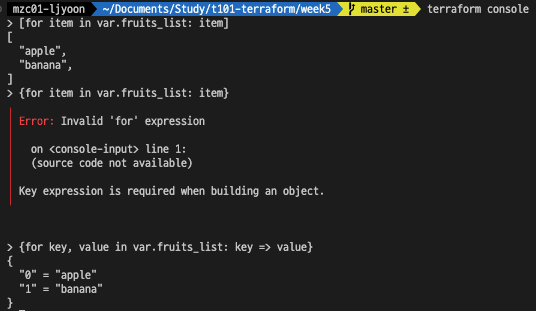
variable "fruits_list" { type = list(string) default = ["apple", "banana"] description = "fruit example" }
![list의 경우도 key, value 형태로 출력할 수 있다.]() list의 경우도 key, value 형태로 출력할 수 있다.
list의 경우도 key, value 형태로 출력할 수 있다.
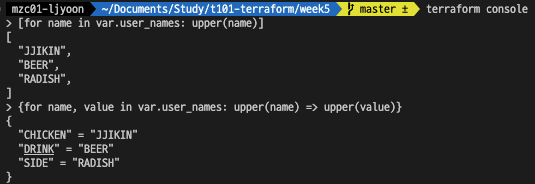
실습 1 - 대문자 변환
1
2
3
4
5
variable "user_names" {
description = "Create IAM users with these names"
type = map(string)
default = { "chicken": "jjikin", "side" : "radish", "drink" : "beer" }
}
실습 2 - for_each + for을 이용한 S3 버킷 이름 일괄 변환 후 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
provider "aws" {
region = "ap-northeast-2"
profile = "ljyoon"
}
variable "fruits" {
type = set(string)
default = ["apple", "banana"]
description = "fruit example"
}
variable "postfix" {
type = string
default = "stage"
description = "postfix"
}
resource "aws_s3_bucket" "mys3bucket" {
for_each = toset([for fruit in var.fruits : format("%s-%s", fruit, var.postfix)])
bucket = "jjikin-${each.key}"
}
- for expression의 결과를 받아서 set 타입으로 변환 후, for_each로 S3 생성을 반복합니다.
- format 내장 함수 : 문자열들의 결합에 사용합니다.
for string directive(문자열 지시자)
문자열 보간(”${var.name}”)과 유사한 구문으로 문자열 내에서 반복문, 제어문을 사용할 수 있습니다.
for string directive 구문
1
%{ for <ITEM> in <COLLECTION> }<BODY>% { endfor }
- COLLECTION : 반복할 리스트 또는 맵
- ITEM : COLLECTION의 각 항목에 할당할 로컬 변수의 이름
- BODY : ITEM을 참조할 수 있는 각각의 반복을 렌더링하는 대상
사용 방법
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
variable "names" { description = "Names to render" type = list(string) default = ["gasida", "akbun", "fullmoon"] } output "for_directive" { value = "%{ for name in var.names }${name}, %{ endfor }" } # apply terraform apply -auto-approve Outputs: for_directive = "gasida, akbun, fullmoon, " # 인덱스 추가도 가능 (Python의 for문 내 변수2개 사용과 비슷하다) output "for_directive" { value = "%{ for i, name in var.names }${i}. ${name}, %{ endfor }" } Outputs: for_directive = "1. gasida, 2. akbun, 3. fullmoon, "
참고
- Terraform DocsㅣFunction
- Terraform DocsㅣExpressions
- 악분님 Youtube
- 가시다님 스터디 자료